Coding and Paper Letter(八十五)
新一期资源整理博客。
1 Coding:
1.阿根廷地质协会(AGA)于2020年8月和9月提供的“地理信息学应用于多专题制图”课程的虚拟课程。
2.R语言包glmmTMB,基于Template Model Builder拟合广义线性混合效应模型。
3.Python库rich,是一个Python库,用于在终端中显示富文本和精美格式。
4.Python库Mici,提供了概率模型中近似推论的马尔可夫链蒙特卡罗(MCMC)方法的实现。
5.在大约2分钟内免费获得MacOS或Linux Shell。
6.OpenGL与GDAL的教程。
7.2020年英国生态学会研讨会材料:用广义线性潜变量模型分析多元生态数据。

8.R语言包getremotedata,它提供协调下载网络上各种可用开放数据集的功能。
9.R语言包opendapr,它提供了使用OpenDAP框架(开源项目,用于 网络数据访问协议),一种广泛用于各类卫星遥感产品下载的框架。
10.像普通书一样简单的hugo文档主题。
11.R语言包tidytable,data.table包的tidy接口。
12.R markdown生成的CV。
13.Python库pint,Pandas的pint支持。
14.Python库uncertainties,它可以执行带有不确定性(又称为“错误传播”)的透明计算。
15.Rocky Linux是一个社区企业操作系统,旨在与Enterprise Linux进行100%错误兼容。
16.王江浩老师在国科大上课的ucasmap课程相关内容。
17.R语言包rBLAST,连接基本局部比对搜索工具(BLAST),以使用Bioconductor基础结构搜索基因序列数据库。
18.一组旨在与Google Earth Engine(GEE)中的Continuous Change Detection and Classification(CCDC)算法的输出进行交互的工具和应用程序。
19.Python库POT,为信号,图像处理和机器学习的最佳传输有关的优化问题提供了多个求解方法。
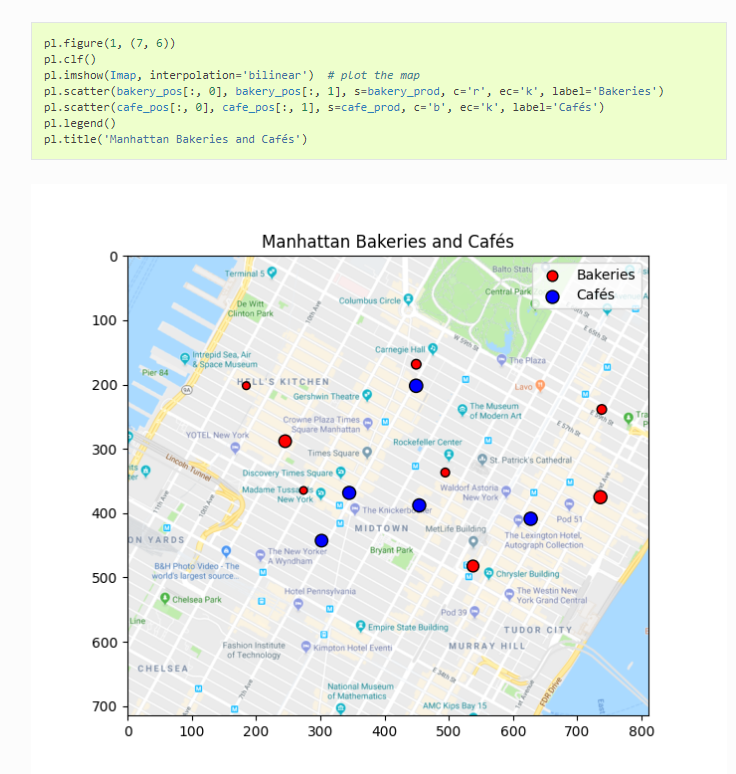
20.R语言包freshAirFinderApp,一个shiny app,目标是在大湾区寻找空气清新之地。
21.一组Python脚本,用于清理和增强GTFS。
22.Python库pyodbc,一个开放源代码的Python模块,使访问ODBC数据库变得简单。
23.AGU 2020年会研讨会资料。主题为开发和维护开源研究软件的最佳实践。
24.2005年以来马来西亚空气污染指数的历史数据(带脚本)。
25.小型OpenGL程序,用于可视化兼容设备的多点触摸输入。
26.Python库intake,一组轻量级的工具,用于在数据科学项目中加载和共享数据。
27.Tengine Lite 由 OPEN AI LAB 主导开发,该项目实现了深度学习神经网络模型在嵌入式设备上的快速、高效部署需求。为实现在众多 AIoT 应用中的跨平台部署,本项目基于原有 Tengine 项目使用 C 语言进行重构,针对嵌入式设备资源有限的特点进行了深度框架裁剪。同时采用了完全分离的前后端设计,有利于 CPU、GPU、NPU 等异构计算单元的快速移植和部署。同时兼容 Tengine 框架原有 API 和 模型格式 tmfile,降低评估、迁移成本。

28.ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,将 AI 带到你的指尖。ncnn 目前已在腾讯多款应用中使用,如 QQ,Qzone,微信,天天P图等。

29.Python库Pint,用于定义,操作和操纵物理量:数值和度量单位的乘积。 它允许它们之间进行算术运算,以及在不同单位之间进行转换。
30.Python库puppeteer cluster,通过puppeteer生成了一个Chromium实例池,并有助于跟踪作业和错误。 如果要爬网多个页面或并行运行测试,这将很有帮助。
31.为rOpensci社区主题和演讲者征集您的“投票”和新想法。
32.该存储库包含一些python代码,其中包含一些传统的变更检测方法,或者提供其原始网站(例如SFA,MAD)以及一些基于深度学习的变更检测方法(例如SiamCRNN,DSFA和某些基于FCN的方法)。
33.这是卡里姆·杜伊布(KarimDouïeb)为瑞士写的著名的可视化版本”Land doesn’t vote, people do”的版本。该版本显示了市政一级受欢迎的“为负责任的企业–保护人权和环境”倡议的成果。 。 通过瑞士公开政府数据平台opendata.swiss检索了此过程中使用的所有数据。
34.R语言包funneljoin,使分析行为漏斗变得容易。
35.CNN网络的Pytorch实现。
36.R语言包robservable,允许将Observable笔记本(或其中的一部分)用作R中的htmlwidgets。
37.从Internet Archive Wayback Machine下载整个网站。
38.R语言包bslib,通过Bootstrap(3或4)Sass从R设置shiny和rmarkdown主题的工具。
39.MLOPS with R: An end-to-end process for building machine learning applications汇报的相关资源。
40.通过Z-Wave和Flask控制的圣诞灯。
minimum viable christmas lights

41.地表温度反演的R markdown文档。
42.使用GeoPandas和PyData堆栈进行地理空间数据分析教程。
43.可持续的免费开源社区网站。
44.开源项目关键度评分项目。
45.transit API,应用程序,数据集,研究和软件的社区列表
46.Python库causal curve,当感兴趣的治疗持续时,可以用这个包基于观察数据执行因果推理。
47.Python库transplant,Python调用Matlab的方法。
48.Covid-19事件预测项目
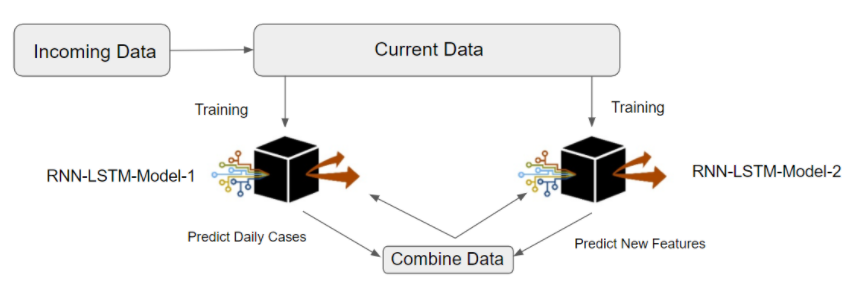
49.R语言包tic,tic的目标是增强和简化使用持续集成(CI)系统的工作。
50.R语言包wrfhydroSubsetter,一组WRF-Hydro(NWM)子模型的域文件供本地化运行的工具。
51.R语言包faraway,包含三本R语言书籍的所有数据与函数。
52.CloudBase Framework 是云开发官方出品的前后端一体化部署工具。

53.蒙彼利埃生物统计学家网络页面。
54.MapLibre GL由社区主导的派生工具maplibre。
55.永久免费开源的导师评价数据、数据爬虫、无需编程基础的展示网页以及新信息补充平台。
56.ipyevents提供了一个自定义窗口小部件,用于将鼠标和键盘事件返回给Python。
57.R语言包BETS,用于获取与分析巴西时间序列的经济数据。
58.Serge Rey,Dani Arribas-Bel和Levi Wolf为地理数据科学书籍提供的入门幻灯片。
59.马尔堡大学环境信息学实验室的材料,组织R数据分析工作流和项目,包括文档。
60.R语言包modleR,一个基于package dismo的工作流,旨在在执行生态位模型时自动执行一些常见步骤。
61.PyMC3模型的示例,包括Jupyter笔记本库。
62.R语言包shinyvalidate,Shinyvalidate为Shiny添加了输入验证功能。
63.R语言2020会议用shiny做数据可视化的研讨会。
64.康奈尔大学课程高级编译。
65.mikejohonson的个人主页。
66.帮你记住你的python装饰器。
67.Python库RavenPy,用于设置和运行水文模型框架Raven。
68.R语言包doc2vec,用于构建Paragraph Vector模型,也称为doc2vec模型。 您可以训练分布式内存(’PV-DM’)和分布式单词袋(’PV-DBOW’)模型。
69.R语言包streamgraph,用于制作流图的htmlwidget。
70.RainBench数据集。
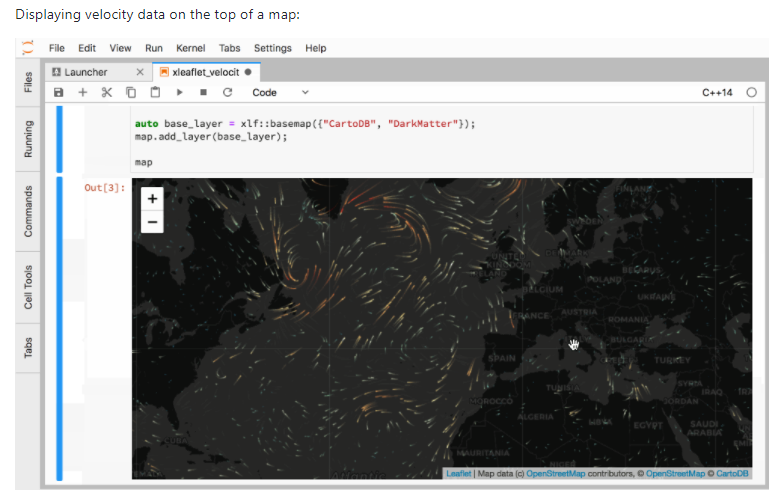
71.’什么是科学’速查表。
72.R语言包ggx,该软件包是ggplot2的附加组件,ggplot2是用于创建出色图形的R软件包,将自然语言转化为ggplot2绘图语句。

73.R语言包OBservData,作物授粉数据库。
74.Leaflet的插件(v1.0.3和v0.7.7),用于创建画布可视化图层,用于显示任意速度(例如风,洋流)的方向和强度。
75.WebGPU学习。
76.R语言包memer,memer是与tidyverse兼容的R包,通常是围绕magick函数进行包装。
77.从NCI文件系统将geotiff转换为云优化Geotiff(cog)。
78.2020年12月9日R-Ladies St.Louis(STL)的演讲的幻灯片和代码。
rladiesSTL dec2020 intro shiny
79.R语言包dftTrafficCounts,目标是在其roadtraffic.dft.gov.uk网站上提供对英国运输部(DfT)提供的数据集的轻松访问
80.Python库volpy,Python中数字高程模型的体积计算(volpy),提供一种以三角不规则网络(TIN)表示的数字高程模型(DEM)计算体积的方法。

81.用于为ReferenceFileSystem进行参考描述的函数。
82.组织Hack Week的工具包。
83.PaddleSeg是基于PaddlePaddle开发的端到端图像分割开发套件,覆盖了DeepLabv3+, U-Net, ICNet, PSPNet, HRNet, Fast-SCNN等主流分割网络。通过模块化的设计,以配置化方式驱动模型组合,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。

84.C-Plan是一种保护决策支持软件,可与GIS链接以映射用于实现明确保护目标的选项。 它是由Matt Watts和Bob Pressey开发的。 它充当Marxan的图形用户界面,可以从C-Plan数据集生成Marxan数据集。
85.hugo的cupper主题。
86.一个用python和pygame编写的台球游戏。
87.Eclipse布局内核(ELK)实现了将图编辑器或查看器连接到自动布局算法的基础结构。

88.使用Flask搭建的经典Python论坛软件。
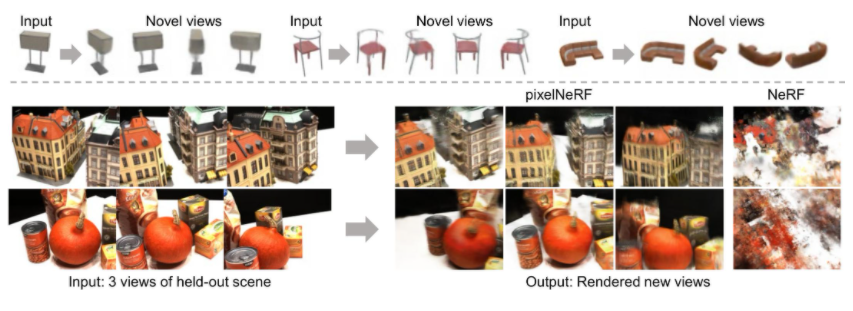
89.pixelNeRF:一幅或几幅图像的神经辐射场。
90.GraphScope是一个统一的分布式阿里巴巴图形计算平台,提供了一个一站式环境,可通过用户友好的Python界面在计算机集群上执行各种图形操作。
91.AKS Engine是旧版ARM模板驱动的方法,用于在Azure上置备自管理的Kubernetes群集。
92.R语言包nimbleDistance,用于在nimble中拟合距离贝叶斯采样模型的函数。
93.Ravens是PyBullet中模拟任务的集合,用于学习基于视觉的机器人操纵,重点是拾取和放置。
94.Python库forestatrisk,可以对热带地区的森林砍伐进行建模和预测。它提供了根据各种空间解释变量估算毁林空间概率的功能。
95.该存储库是BBC R&D在制作合成声音时产生的脚本和指南的集合。 我们将这种基于深度卷积网络的高效可训练文本语音转换系统的实施作为指导,并将其作为指导工作的基础。 提供的文档将说明我们采取的不同步骤,以便从中获得最佳效果,从而迅速而廉价地发出新声音。
96.R语言包validate,验证的R-package使得根据域知识检查数据是否符合您的期望变得非常容易。 通过允许您定义独立于代码或数据集的数据验证规则,它可以工作。 接下来,您可以使用规则处理数据集或其各种版本。
97.R语言包tinter,调色器提供了一种生成单色调色板的简单方法。

98.DGGRID是一个免费软件程序,用于创建和处理由Kevin Sahr创建和维护的离散全球网格。
99.R语言包mcor,蒙大拿州气候办公室的核心R包。
100.Python库rHEALPixDGGS,实现了rHEALPix离散全球网格系统(DGGS)。
101.DGGRID是一个命令行应用程序,旨在生成和操作二十面体离散全局网格(DGG)。
102.JupyterHub 2020年冬季地理空间数据分析课程的docker镜像。
103.韩国的人口格网建模
104.MIT感知实验室的Treepedia项目。利用街景图像识别树木。
105.oci-cloud-controller-manager是用于Oracle Cloud Infrastucture(OCI)的Kubernetes Cloud Controller Manager实现。
106.将Red Hat Enterprise Linux 7.6作为EKS工作节点运行
107.Cling是基于Clang和LLVM编译器基础结构的交互式C ++解释器。
108.xeus-cling是基于C ++解释器cling和Jupyter协议xeus的本机实现的C ++ Jupyter内核。
109.mkcert是制作本地信任的开发证书的简单工具。 它不需要任何配置。
110.KernelFunctions.jl为内核函数提供了一个灵活而完整的框架,可以对输入数据进行预转换。
111.Mundane是由BoringSSL支持的Rust密码术库,它很难被滥用,符合人体工程学且性能优异(按此顺序)。
112.该存储库包含用于使用HashiCorp Packer构建自定义Amazon EKS AMI的资源和配置脚本。 这与Amazon EKS用于创建官方经Amazon EKS优化的AMI的配置相同。
113.该项目提供了一个操作员来管理yarn的节点管理器和资源管理器。 它支持大数据系统顺利迁移到kuberenets。
114.Spack是一个多平台程序包管理器,可构建和安装软件的多个版本和配置。 它可以在Linux,macOS和许多超级计算机上运行。
115.Xtensor C ++多维数组库的R接口。
116.xtensor是一个C ++库,用于使用多维数组表达式进行数值分析。
117.现代C++的json。
118.仅限小型头文件的C ++库,用于编写多平台终端应用程序。
119.jupyter-leaflet地图可视化库的C ++后端。
120.Python库conan,C/C++的包管理器。
121.R语言包winch,Winch为跨R和C函数调用的调用链提供堆栈跟踪。
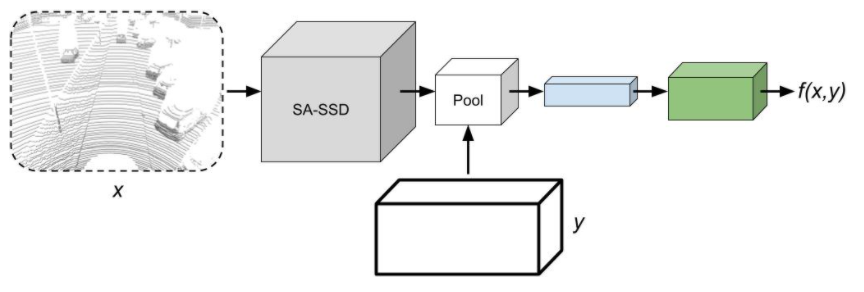
122.英国邮政编码和地理位置API,提供开放数据。
123.Rasterio插件可从Cloud Optimized GeoTIFF数据集中读取墨卡托瓦片。
124.R语言包tabnet,TabNet的R语言实现,细心的可解释表格学习。
125.Regression Modeling in People Analytics手册。
peopleanalytics regression book
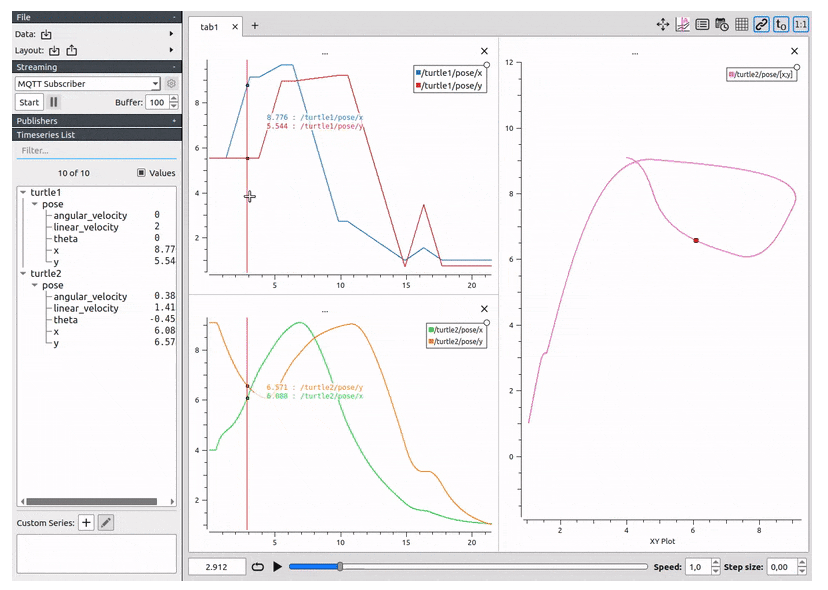
126.”Accurate 3D Object Detection using Energy-Based Models”的官方实现。
127.Julia的包管理器。
128.nCompiler旨在提供一个新的R开发工具,用于代码生成C ++并轻松在R和C ++之间进行接口。
129.Julia包的示例。
130.INLG 2020论文”RecipeNLG: A Cooking Recipes Dataset for Semi-Structured Text Generation”的代码实现。
131.PlotJuggler是一种可视化时间序列的工具,它快速,强大且直观。
132.一组Google Earth Engine的常用调色板。
133.使用遥感和水费预算产品的农场尺度土壤水分。
134.Web 3D GIS引擎。
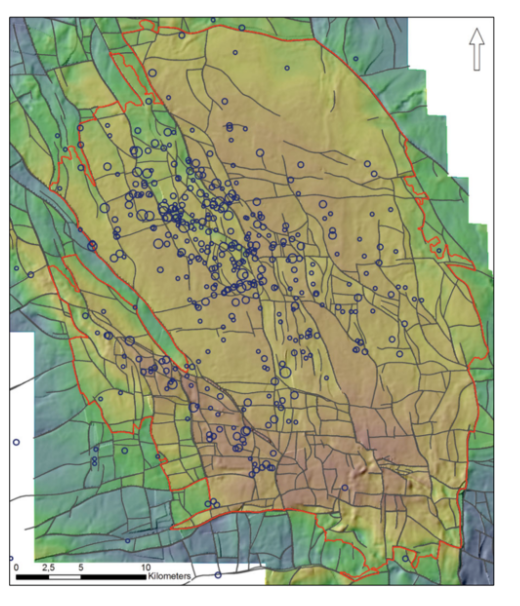
135.该数据集包含一个静态地质模型及其各个组成部分:来自6000口测井的数据,叠前深度的地震量,地震层位以及大量已解释的断层。
136.这项正在进行的工作是将Google EarthEngine(GEE)API功能集成到Python 3.x语言的HydroShare中,以用于犹他州立大学CEE/PSC/WATS 5003/6003土地表面遥感春季班。
137.Esri CityEngine库,带有用于大型项目的辅助规则和脚本。

138.jp_doodle使实现特殊目的的交互式可视化变得容易。 它旨在促进定制科学数据表示和交互式探索工具的开发。
139.阿伯丁研究小组教程项目。
140.Python科学堆栈,编译为WebAssembly。
141.R语言包nomadsNC,目标是从NWC国家水模型中下载最新的预测,并将数据用于时间序列访问。 您必须安装NCO才能运行此软件包。
142.关于贝叶斯因素的个人论文的论文。
143.帝国理工学院环境与健康中心讲习班。
144.面向地球科学家的社区教育资源。
145.有关为澳大利亚海洋数据网生成标准NetCDF文件的模板和代码的存储库。
146.Learning Ansible 2.7第三版。
Learning Ansible 2.X Third Edition
147.Deno是使用V8并内置于Rust的JavaScript和TypeScript的简单,现代且安全的运行环境。
148.确定使用Pangeo工具(GDAL,Rasterio,Xarray,Dask)访问越来越多的COG数据的最佳实践。
149.最小巧、最准确、最全面、最实用的中国大陆 GeoIP2 数据库及 IP 地址段。
150.Visual Studio Code的R拓展。
151.快速,耐错字的模糊搜索引擎,可提供令人愉悦的搜索体验。
152.提供了用于模拟印欧航线上常见玫瑰雀的最佳资源和风迁路线的代码。我们对风和资源的一般最佳迁徙路线进行了建模,从追踪的普通玫瑰雀的五个繁殖地点(芬兰,瑞典,德国,捷克和保加利亚)到巴基斯坦和印度的非繁殖地点。
Optimal migration along the Indo European Flyway
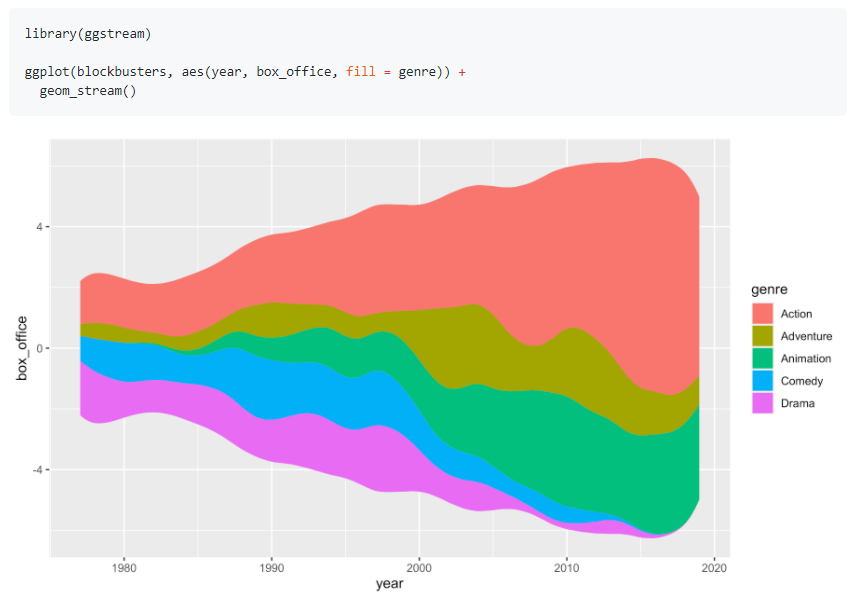
153.R语言包ggstream,ggplot2的拓展包,用来绘制河流图。
154.自托管应用程序,可通过REST访问IMAP和SMTP帐户。
155.微软开源地图项目。
156.国家环境信息中心(NCEI)API的接口。
157.Julia包Diversity,它提供了用于测量元社区(例如生态系统)及其组成子社区的alpha,beta和γ多样性的功能。
158.Python库parsac(以前称为acpy),用于并行运算灵敏度分析和自动校准。它用于分析需要大量时间才能运行的模型。 因此,它着重于存储和利用每个模型结果,并在单个计算机或计算机集群上并行执行模型。
159.用Python和Julia实现HYMOD降雨径流模型。
160.这是用易于阅读的JavaScript编写的现代编译器所有主要部分的极简示例。
161.Python练习材料。
162.Python库SALib,敏感性分析方法,包含Sobol,Morris,分数阶乘和FAST方法。
163.说明了如何使用子文档将插图的snowflakes添加到R Markdown。
164.带有requirements.txt文件说明与Binder兼容的Python库。
165.具有environment.yml文件的与Binder兼容的Python库。
166.R语言包mlr3learners,为mlr-org团队维护的mlr3提供了重要的学习者。 可以在GitHub上的mlr3extralearners包中找到其他学习者。
167.mlr3提供超参数调整。可以设置和组合各种终止条件。
168.这使用反向工程的ReMarkable API库将文件从Zotero集合自动传输到reMarkable文件夹。
169.华北平原建设用地制图指南。
North China Plain GEE Organized

170.R语言包rmapshaper,提供对Matthew Bloch出色的mapshaper工具的访问,该工具同时具有Node.js命令行工具和交互式Web工具。

171.Github用户的学生的机器学习项目,并且学生同意分享。
MachineLearning StudentProjects
172.Python库ocetrac,用于跟踪海洋热浪。
173.R语言包diffabsr,将来自SOLEIL同步加速器的DIFFABS光束线的数据转换为R兼容格式。 此外,它还提供了将原始光谱转换为元素计数和/或浓度的功能。
174.OpenGV是解决几何视觉问题的计算机视觉方法的集合。 它由上海科技大学移动感知实验室主持和维护。
175.Jupyter与其他公司的实时协作。
176.分布式系统的经典材料。
177.GridIndex是可传递的2D空间索引。
178.使用Mapbox GL JS轻松为您的应用生成地形立交的界面。

179.在kubernetes运行第一个你的程序。
180.一个用create-next-app引导的Next.js项目。
181.2020年印度scipy会议下pysal的研讨会。
182.R语言包rinvest,Python invest模型的R接口。
183.Pymc3里的隐马尔科夫链-蒙特卡洛模拟。
184.R和RStudio用于教授可重复科学的材料。
185.GeoNode是一个开放源代码平台,可促进地理空间数据的创建,共享和协作使用。
186.Python cf软件包是一个基于CF数据模型的完整实现构建的Earth Science数据分析库。气候和预报元数据公约(CF-1.6)的数据模型,并带有软件实现。

187.该存储库包含用于从Wikipedia对英国境内地点的描述中提取地理实体的代码。
188.Python库c lasso,一个用于约束稀疏回归和分类的Python包。
189.Python和Java的Plain Paxos实现。
190.SuperflexPy:水文建模的灵活语言。
191.地理空间公司的资源列表。
192.如何使用Libtorch构建你的C++应用。
193.VaRest是Unreal Engine 4的插件,可使REST服务更易于使用。

2 Paper:
研究城市森林生物量的空间分布及其潜在影响因素将为配置城市绿地提供有用的见识。尽管中国正经历着前所未有的城市化规模,但城市森林生物量分布的空间格局作为城市景观的重要组成部分尚未得到充分研究。使用地理检测器方法,本研究研究了四种地理因素(GFs)(主要树种,森林类别,土地类型和年龄组)对中国西安市1480个样地中城市森林地上生物量分布的影响。结果表明:(1)西安市地上生物量和4个GF在空间分布上存在明显的异质性。 (2)影响地上生物量模式的优势树种和年龄组是主要的GF,独立q值(用于量化研究中GF的影响的统计量度)分别达到0.595和0.202,而森林种类和土地类型与地上生物量的空间变化之间存在弱联系,其q值分别为0.087和0.076。 (3)这四个GF之间的相互作用也往往有助于地上生物量的分布方式。与从因素独立获得的影响总和相比,GF之间的相互作用产生了更大的影响。我们的结果表明,使用地理探测器的方法在市区是一种有用的工具,可以揭示地上生物量的驱动模式,并为城市规划和管理提供参考。利用地理探测器分析AGB的空间异质性与驱动因子。这个方面一个比较有意思的问题是如何定义urban forest。
人类活动产生了各种复杂的功能区域,并可能影响功能区域的现有计划。了解人类活动与功能区域之间的关系是基于轨迹识别实时城市功能区域的关键。很少有先前的研究对人和区域的交互信息进行分析以识别功能区域。人类活动与居住区之间的关系是城市功能区中最具代表性的关系,因为居住区覆盖范围广且与人类生活紧密相关。本文的目的是提出一种通勤活动和居住区模型,以量化人类活动与城市居住区之间的相关性。在此模型中,人类活动由高斯混合模型算法提取的热点表示,而居民区由POI(兴趣点)数据表示。该模型显示,人类活动和居住区呈对数关系。通过从共享电动自行车轨迹中反演滕州市的城市居民区,进一步评估了CARA模型。与实际地图相比,准确度达到83.3%,证明了该模型的可靠性和可行性。该研究为基于轨迹数据的功能区识别提供了一种新方法,有助于制定以人为本的城市政策。利用共享电动自行车轨迹数据分析人类活动与功能区的关系。数据和方法比较新颖。一个问题在于共享电动自行车的数据代表性,本质上属于有偏数据,同时居民区用POI的点数据表示,可能一定程度上也造成了结果的不确定性。
台风是一种环境威胁,主要影响全世界的沿海地区。自然和社会经济因素对台风灾害造成的损失的互动影响有待进一步研究。在这项研究中,GeoDetector用于量化自然和社会经济因素的决定力及其对2018年台风”山竹”造成的中国东南广东和广西省房屋倒塌率的互动影响。我们进一步确定了影响该因素的主导因素灾难的损失。然后介绍了空间关联方法的局部指标,以解释在主导因素影响下灾害损失的空间异质性。结果表明,自然因素和社会经济因素均显着影响房屋倒塌率。最大降水量是主要因素,其q值为0.21,其次是坡度和海拔,其q值分别为0.17和0.13。人口密度和人均国内生产总值的q值分别为0.15和0.13。在所有影响因素的交互作用中,海拔和砖木房屋比率的交互作用对房屋倒塌率的影响最大(q = 0.63)。这些结果可有助于制定更具体的安全和财产保护政策。分析台风’山竹’的灾后影响评估。并且分析不同自然社会经济因素造成的影响。
将人类活动模式数字化的准确,详细的地理信息在应对自然灾害方面起着至关重要的作用。自愿提供的地理信息,特别是OpenStreetMap(OSM),在提供人类住区知识以支持人道主义援助方面显示出巨大潜力,而OSM的可用性和质量仍然是一个主要问题。现有的评估OSM数据质量的大部分工作都集中在外部分析或内在分析上,这在一定程度上不足以实现人道主义制图方案。本文旨在从社会感知和遥感的综合角度探索OSM缺失的堆积区。首先,应用分层DBSCAN聚类算法,生成带有地理标记的推文的聚类作为人类活动区域的代理。然后,提出了一种基于深度学习的模型,该模型在现有OSM数据上进行了微调,以进一步映射缺失的堆积区域。莫桑比克共和国于2019年受到飓风伊代(Idai)和肯尼斯(Kenneth)的袭击,被选为研究区域,在全国范围内评估拟议的方法。结果,识别并映射了13个OSM缺失的堆积区域,总体精度超过90%,与最新产品相比具有竞争力,这证实了所提出方法的有效性。Top期刊ISPRS的一篇雄文,结合Twitter数据,聚类算法和深度学习对OSM缺失的建成区进行补充制图。
害怕犯罪会导致对生活和主观幸福感的满意度降低。害怕犯罪的指标因社会和文化背景而异,户籍(户籍)状况导致中国本地户口与非本地户口居民之间的权利不平等。为了提高人们对安全的认识,本研究将户口作为社会脆弱性的指标,并研究了户口,感知的邻里条件和对犯罪的恐惧之间的关系。二元逻辑回归模型用于分析2016年中国广州市广州市社区安全项目(PPSGN)中获得的1727名居民。结果表明,妇女,受害经历,身体和社会障碍以及社区警务与居民对犯罪的恐惧有关。尽管户口地位对犯罪的恐惧没有统计学上的显着影响,但户口地位显着减轻了感知的邻里条件对犯罪恐惧的影响。也就是说,感知到的邻里状况对恐惧的影响取决于一个人的户籍状况:非本地户籍,对社会混乱的感知对恐惧的危害更大,对社会融合的感知对恐惧的帮助作用则较小。总而言之,本研究通过揭示户口对中国城市恐惧的条件影响,为国际文献增色不少。柳林老师团队的成果,分析邻里环境以及社会经济因子对犯罪恐惧的影响。犯罪地理学与心理学的交叉研究。
语境:城市群是城市的高级空间组织,通常由城市发展到一定水平时的城市化过程引起,通常与更高的人口密度和一定密度的建筑环境有关。但是,与针对特定城市的各种研究相比,城市群仍处于研究不足状态,尤其是在定量识别城市群时空演变方面。目标:本研究旨在确定2000年至2012年中国城市群的边界,并探讨城市群的时间演变和空间差异。方法:首先,使用适当的夜间光数字(DN)阈值来确定城市群的核心区域。其次,利用平均斑块面积和重力模型确定城市群的受影响区域。第三,以中国23个主要城市群为中心进行时空对比。结果:到2012年,最发达的长三角和珠江三角洲城市群达到世界水平,其中京津冀城市群为区域一级,亚区域级为11个城市群。在2000-2012年的研究期间,中国南部和北部之间,或沿海与内陆之间城市群的区域差异保持稳定。与西部城市群相比,东部城市群的向外扩张有所减速。从2000年到2012年,城市群的总体发展模式从核心扩张向边缘发展转变,而2006年以后城市群扩张速度放缓。结论:夜间光数据可有效探索城市群的时空演变。彭建老师团队的研究,发表在top期刊Landscape Ecology,从夜间灯光遥感角度分析中国城市群的时空演变规律,工作量较大。
地理参考数据源的增长要求使用高级匹配方法来提高地理空间数据处理(如地图合并)的可靠性。现有的匹配方法主要集中于实体规模或区域规模的相似性度量。结合实体规模和区域规模相似性的度量可以在各种情况下提供合理的匹配结果。在本文中,我们提出了一个地理参考图模型,该模型集成了多尺度相似性以进行数据匹配。具体地,在面积比例度量的约束下,通过实体比例度量来识别对应数据对象的匹配。所建议的地理参考图模型中的节点通过其质心表示多边形,而图中的链接则根据预定义的规则连接节点(即质心)。然后,我们开发一种算法来识别多对多匹配。我们在实际实验中使用OpenStreetMap数据演示了提出的图形模型和算法。实验结果表明,所提出的地理参考图模型可以有效地整合不同数据集之间的上下文和地理空间数据匹配的位置和形式距离。葛咏老师团队发在IJGIS上的一篇雄文,一个地理参考图模型用于多源数据匹配融合。
在基于遥感影像的土地利用和土地覆盖分类中,学习失衡是一个普遍的问题。学习不平衡会导致分类准确性降低,甚至导致少数群体的遗漏。在本文中,提出了一种基于极端梯度增强(ISS-XGB)的公正半监督学习策略,以对数据不平衡的超高分辨率(VHR)图像进行分类。 ISS-XGB通过使用几个半监督分类器来解决多分类问题。它首先采用多组未标记数据来消除训练样本的不平衡,然后利用基于梯度增强的回归来模拟具有正样本和未标记样本的目标类别。在这项研究中,在八个不同失衡状况的研究区域进行了实验。结果表明,与最常用的分类方法(即随机森林(RF),XGB,多层感知器(MLP)和支持向量机(SVM))相比,ISS-XGB提供了可比但更稳定的性能,阳性和未标记的学习(PU学习)方法(PU-BP和PU-SVM),以及典型的基于合成样本的不平衡学习方法。尤其是在极端不平衡的情况下,ISS-XGB可以为少数族裔提供高精度,而不会损失总体性能(平均总体准确性达到85.92%)。所提出的策略在解决遥感分类不平衡问题方面具有很大的潜力。VHR影像的分类不平衡问题解决策略。
尽管已证明短期暴露于细颗粒物(PM2.5)空气污染会导致血压升高(BP),但有关中国全国环境PM2.5与血压水平之间的关联以及如何关联的证据有限可能会改变。这项研究试图探索在低于中国现行国家环境空气质量标准(NAAQS)的水平下暴露于PM2.5引起的急性BP变化。基于对超过100万成年人的时空研究,我们将BP测量值与来自多个来源的PM2.5的每日估算值(即原位观测,气溶胶的卫星测量值和空气质量模型的数值模拟)联系起来,并针对多个个体进行了调整,通过限制将短期PM2.5暴露低于75μg/ m3(即中国的24小时PM2.5的NAAQS)的个体的子集进行分析,我们进一步建立了以下水平的模型,并进一步推导了以下标准模型。我们进一步探索了BP-PM2.5关联随污染水平和不同人口群体的变化。经过全面调整后,PM2.5的10μg/ m3升高与收缩压的0.049(95%置信区间,CI:0.041,0.057)mmHg,0.022(95%CI:0.017,0.027)显着相关。 )舒张压增加mmHg,高血压风险增加0.77%(95%CI:0.62%,0.92%)。对于BP和高血压,暴露-反应曲线在低浓度时呈线性,无阈值效应,在高浓度时呈亚线性。低于当前的NAAQS,人口水平的关联仍然具有统计学意义,甚至更强。低于NAAQS PM2.5增加10μg/ m3与高血压风险增加1.95%(95%CI:1.44%,2.47%)有关。特定的亚群更容易暴露于PM2.5。这些发现可以帮助支持决策者修改相关环境法规以保护公众健康的决策。短期PM2.5污染暴露对健康效应(血压水平)的研究。非常不错的一个环境流行病学与环境健康研究。清华大学张强老师团队成果。
10.Global Carbon Budget 2020/2020年全球碳预算
在不断变化的气候中,准确评估人为二氧化碳(CO2)排放及其在大气,海洋和陆地生物圈之间的重新分配(“全球碳预算”)对于更好地了解全球碳循环,支持制定气候政策至关重要,并预测未来的气候变化。在这里,我们描述并综合了数据集和方法,以量化全球碳预算的五个主要组成部分及其不确定性。化石的二氧化碳排放量(EFOS)基于能源统计数据和水泥生产数据,而土地利用变化(ELUC)的排放量(主要是森林砍伐)则基于土地利用和土地利用变化数据以及簿记模型。直接测量大气中的CO2浓度,并根据浓度的年度变化计算其增长率(GATM)。海洋CO2汇(SOCEAN)和陆地CO2汇(SLAND)是通过受观测约束的全球过程模型估算的。由此产生的碳预算失衡(BIM),即估计的总排放量与大气,海洋和陆地生物圈的估计变化之间的差,是衡量数据不完善和对当代碳循环的了解的一种度量。所有不确定度均报告为±1σ。在过去的十年中(2010-2019年),EFOS为9.6±0.5 GtC yr-1(不包括水泥碳化池)(包括水泥碳酸化池时为9.4±0.5 GtC yr-1),ELUC为1.6±0.7 GtC yr-1 -1。在同一十年中,GATM为5.1±0.02 GtC yr-1(2.4±0.01 ppm yr-1),SOCEAN 2.5±0.6 GtC yr-1和SLAND 3.4±0.9 GtC yr-1,预算不平衡BIM为- 0.1 GtC yr-1表示过去十年中估计的源和汇之间的接近平衡。仅在2019年,EFOS的增长仅约0.1%,化石排放增加到9.9±0.5 GtC yr-1(不包括水泥碳化池)(包括水泥碳酸化池时为9.7±0.5 GtC yr-1)和ELUC人为CO2排放总量为11.5±±0.9 GtC yr-1(42.2±±3.3 GtCO2)为1.8±0.7 GtC yr-1。同样在2019年,GATM为5.4±0.2 GtC yr-1(2.5±0.1 ppm yr-1),SOCEAN为2.6±0.6 GtC yr-1,SLAND为3.1±1.2 GtC yr-1,BIM为0.3 GtC 。 2019年全球平均大气CO2浓度达到409.85±0.1ppm。2020年的初步数据(考虑了COVID-19引起的排放变化)表明,相对于2019年,EFOS相对于2019年减少了约-7%(中值)。来自四项研究的单独估计值分别为-6%,-7%,-7%(-3%至-11%)和-13%。总体而言,在1959年至2019年期间,对全球碳预算各组成部分的均值和趋势进行了一致的估算,但对于CO2通量的半年代际变化,仍存在高达1 GtC yr-1的差异。比较来自各种方法和观察结果的估计值表明:(1)过去十年间,土地利用变化排放的平均值和趋势没有共识;(2)不同方法之间关于土地二氧化碳通量大小的持续低一致性。 (3)在热带以外,特别是在南大洋,不同的海沉方法之间存在明显的差异。该实时数据更新记录了此新全球碳预算中使用的方法和数据集的变化以及与该数据集以前的出版物相比在了解全球碳循环方面的进展(Friedlingstein等,2019; LeQuéré等。 ,2018b,a,2016、2015b,a,2014、2013)。这项工作中提供的数据可在https://doi.org/10.18160/gcp-2020(Friedlingstein等人,2020)获得。全球碳预算项目。非常全面的碳核算项目数据。值得关注。
邻里影响平均问题(NEAP)是一个主要的方法论问题,可能会影响对暴露于与流动性相关的环境因素(例如空气/噪声污染)的个体暴露评估的准确性。本文着眼于室外地面臭氧作为主要的空气污染物,利用3790个人的一日活动旅行日记数据,研究了NEAP在评估洛杉矶人口空气污染中的社会人口统计学差异。它解决了两个问题:(1)NEAP如何影响人们空气污染暴露中社会人口统计学差异的评估? (2)哪些以居民为基础的暴露人群较高,没有平均邻域效应?我们的空间回归模型的结果表明,当人们的日常活动被忽略时,由于不同社会/种族群体平均邻里效应的表现形式不同,因此对人们在室外地面臭氧暴露中的社会人口统计学差异的评估可能是错误的。我们的空间自logistic回归模型的结果表明,非劳动者(例如,失业者,家庭主妇,退休者和学生)没有经历向下平均化的可能性:他们经历向下平均化的可能性要低得多,这可能会降低他们的高暴露水平在他们的居民区旅行到其他街区时(因此处于双重不利地位)。因此,为了避免在环境不平等研究中得出错误的结论和无效的公共政策,在未来与人口流动相关的环境因素相关的社会人口学差异研究中考虑NEAP至关重要。关美宝老师团队的成果,分析NEAP对环境暴露与健康效应相关的一个实证研究案例。结合时空行为地理学的典型数据进行分析。
12.Analyzing Asymmetric City Connectivity by Toponym on Social Media in China/在中国社交媒体上按地名分析不对称的城市连通性
在移动和大数据时代,城市之间的联系已成为城市和区域研究中讨论最广泛的主题之一。确定的一个问题是城市连接不对称,部分原因是数据可用性。我们基于从社交媒体数据中提取的位置和地名(地名)提出了一种数据驱动的方法,以评估城市之间的不对称连通性。假定城市i的名称在位于城市j的帖子中出现的频率更高,则意味着该城市i对城市j的影响力要强于其他城市。此外,我们已经开发了一组度量标准,例如相关性指数,影响指数,链接强度指数,依赖性指数和结构相似指数,以表征这种相互作用。考虑到城市之间不断发展的相互作用,这种连通性度量框架还可以用于支持智能规划。案例研究了中国城市系统的时空结构。叶信岳老师团队的成果,社交媒体地理学的一个应用,通过社交媒体数据以及地名出现频率构建起的城市联系强度模型。非常有意思的一个研究。
颗粒物(PM2.5和PM10)的环境浓度是监测与生活条件相关的空气质量的重要指标。估计PM2.5和PM10的大多数现有方法都采用遥感气溶胶光学深度(AOD)产品作为主要变量。但是,AOD产品中丢失数据的覆盖范围通常很大,这可能给研究人员带来不便。为了有效解决这一问题,我们的研究探索了一种新颖的方法,即使用PM2.5和PM10的前体和化学成分数据集代替AOD产品。具体来说,根据Sentinel-5P和GEOS-FP,估计中国全天的PM2.5和PM10周围环境浓度为5公里(0.05°)。在本文中,利用光梯度增强机来训练估计模型,它将完全融合多源数据。为了进行比较,在类似的框架中采用了VIIRS的Deep Blue AOD产品作为基准(基于AOD)。验证结果表明,通过所提出的方法可以很好地估算环境浓度,对于PM2.5(PM10),基于样品的交叉验证R2和RMSE分别为0.93(0.9)和8.982(17.604)μg/ m3。同时,在不同情况下(例如,整体和季节性),所提出的方法比基于AOD的方法具有更好的性能。相对于中国以前的相关工作,我们方法的估计精度也令人满意。此外,正如预期的那样,PM2.5和PM10的所有前体和化学组成的所有变化都对所提出的方法中的估算有积极贡献。关于制图结果,通过提出的方法得出的估计结果呈现连续的空间分布,并且可以准确表示PM2.5和PM10的季节性变化。可以得出结论,本研究的全覆盖估计结果有利于在AOD值缺失的地区进行PM2.5和PM10的研究。通过化学传输模型输出结果来替代缺失的AOD估算PM2.5和PM10的制图研究,非常有意思的一个研究。目前还在大气化学top期刊ACP公开评审,感兴趣的同学也可以comment。
近年来, 出现了越来越多的基于大数据的流动性研究, 揭示了人们在旅行中的行为和活动模式。但是, 数据真实性问题及其对知识发现过程的影响, 目前鲜有研究。本文探讨了手机信令数据(MSD)在描述流动性模式中的数据真实性问题。首先讨论了影响人类流动性模式估算的MSD位置不确定性问题, 然后研究了现有的两个解决方法(聚类法、时间窗口法)。我们还提出一个新方法, 可以克服上述两种方法的某些缺陷。将这三种方法用于MSD大数据, 我们发现, 不同的数据预处理方法, 可能会很大程度上改变数据的特征, 并进一步影响对人类流动性模式的描述和解释。对三种方法的输出结果, 我们计算了四个流动性指数(旅行数、活动点位数、停留总时间、活动熵), 发现三种方法对(与位置不确定性相关的)个体流动性估算有不同的影响。分析结果表明, 我们应更多地关注数据驱动流动性研究中的真实性问题、及其对地理空间研究的可复制性、可重现性的意义。港理工徐阳老师的研究,分析手机信令数据的位置不确定性问题,实际上这个问题是非常关键的,手机信令数据的地理定位依赖于基站的位置,可能造成小尺度的流动性估算不确定性。